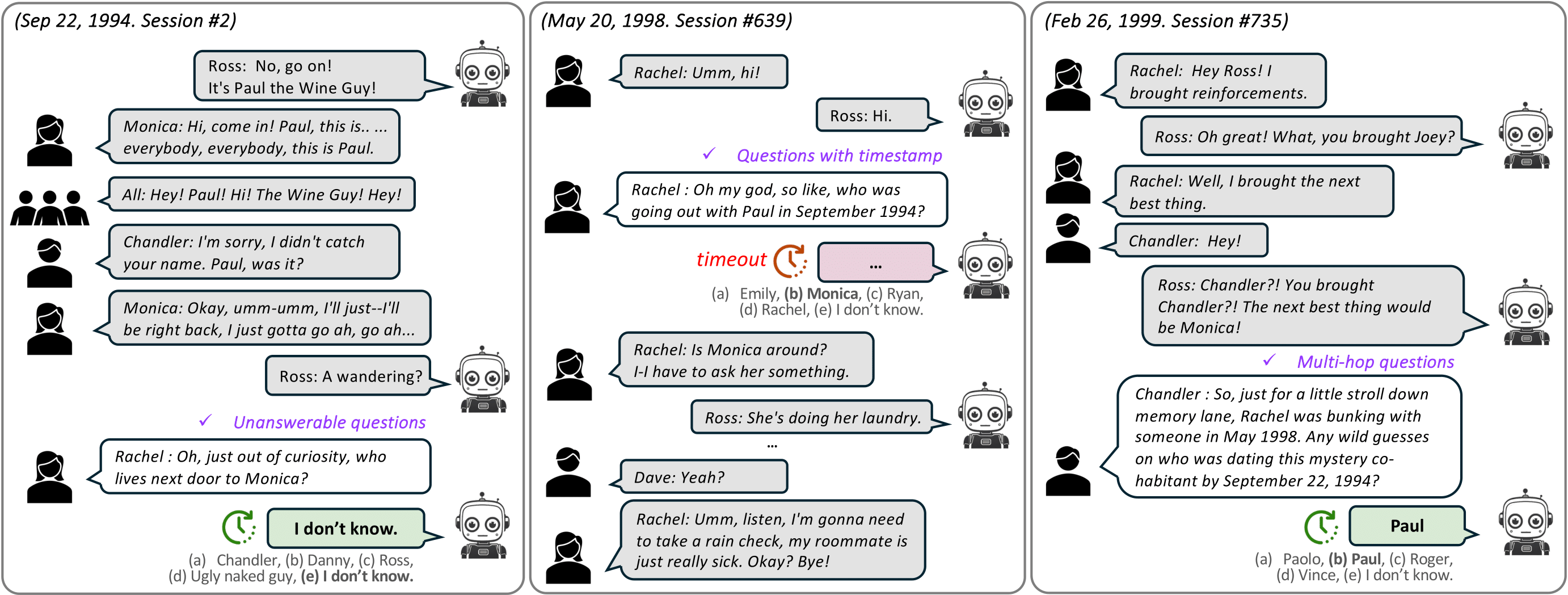
DialSim places an agent in the role of the main character of a TV show, engaging it in an extensive conversation based on the show’s scripted content. During this conversation, the agent is evaluated for its ability to respond appropriately to spontaneous questions from other speakers within a predefined time limit (e.g., 1s / 3s / 5s). The agent should be able to answer questions based on the information from the past dialogue and acknowledge when it does not know the answer. DialSim simulates three different dialogue environments based on scripts from popular TV shows (i.e., Friends, The Big Bang Theory, and The Office), and it has the following four main features.
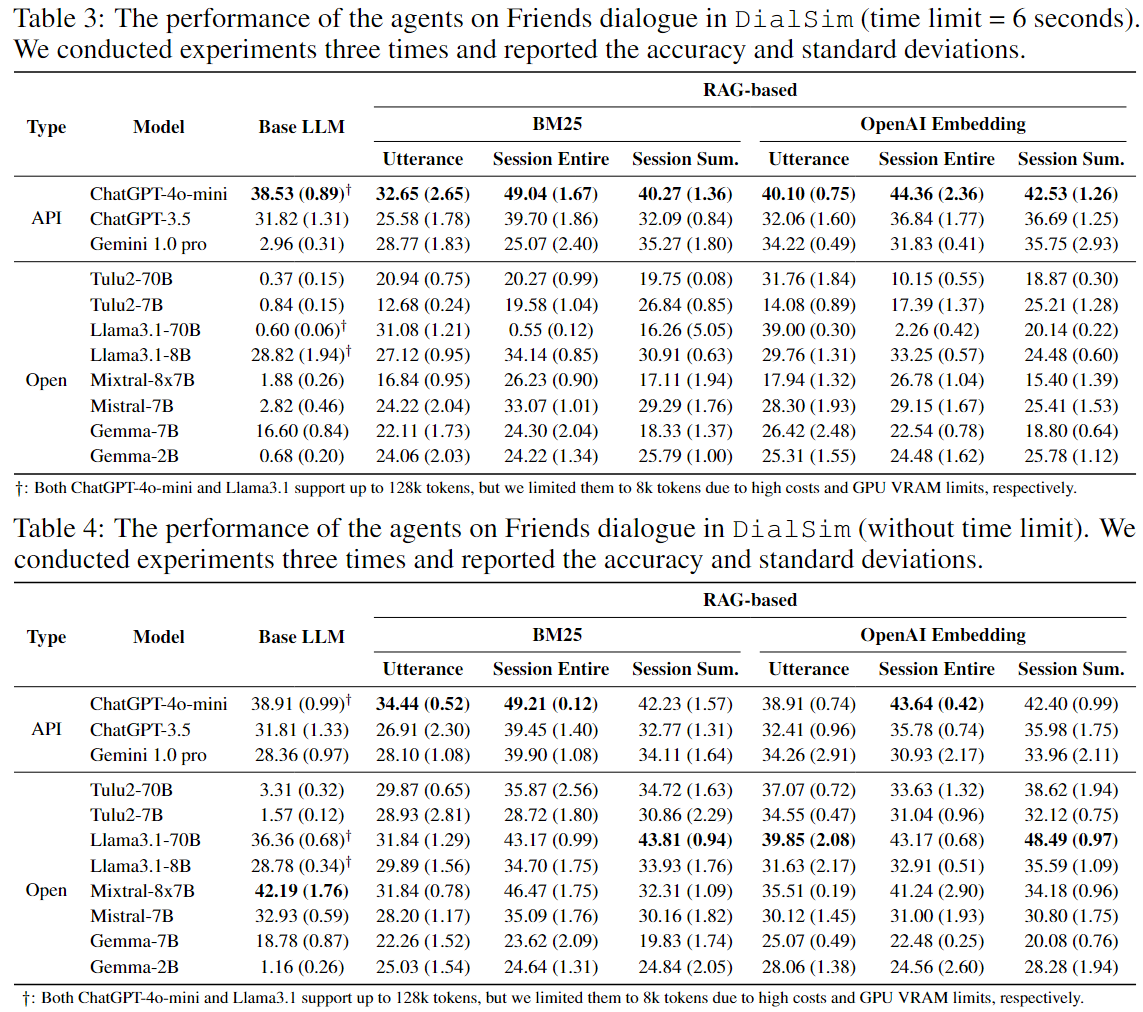
Time-Constrained Evaluation: For a conversational agent to function effectively in real-time, the agent must be capable of updating its memory and generating responses on the fly. To evaluate this, DialSim measures the accuracy of responses within a predefined time limit. To the best of our knowledge, this is the first work that evaluates the performance of a conversational agent in a time-constrained environment.
Extensive Long-Term Multi-Party Dialogue: DialSim simulates multi-party dialogues averaging 350k tokens in length, making it the longest dataset among existing long-term dialogue datasets. Throughout the simulation, the agent encounters complex questions that require comprehension and reasoning across several multi-party sessions, ensuring a thorough assessment of its long-term dialogue understanding capabilities.
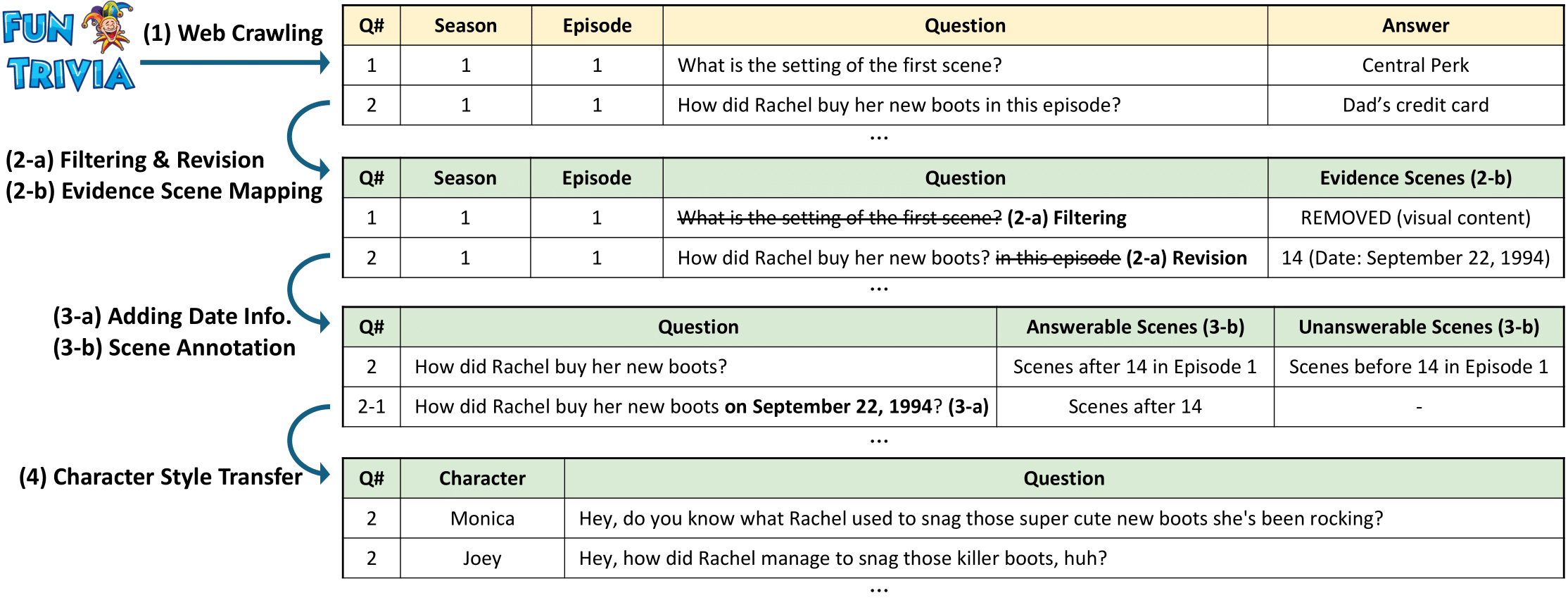
Diverse and High-Quality Question-Answer Dataset: We generated an average of 1,000 unique questions per session using two methods. First, we collected and refined questions from a fan quiz website that covers key events in each TV show. Second, we extracted temporal knowledge graphs for each session to formulate complex, multi-hop questions based on these graphs. We employed ChatGPT-4 to refine the fan quizzes and extract the knowledge graphs, ensuring high quality through manual review by the authors.
Randomized Questioning: DialSim features an average of 1,300 conversation sessions occurring over a period of five years, as depicted in the corresponding TV show. For each session, a randomly selected character asks a question that is randomly sampled from an average of 1,000 candidates, at a random time. This setup allows us to test whether an agent can respond appropriately in a challenging and unpredictable environment, suitable for rigorous evaluation of conversational agents. Additionally, since a random set of questions is given for each test, repeating the tests multiple times allows us to measure the agent's performance variability and reliability.
@article{kim2024dialsim,
author = {Kim, Jiho and Chay, Woosog and Hwang, Hyeonji and Kyung, Daeun and Chung, Hyunseung and Cho, Eunbyeol and Jo, Yohan and Choi, Edward},
title = {DialSim: A Real-Time Simulator for Evaluating Long-Term Multi-Party Dialogue Understanding of Conversational Agents},
journal = {arXiv preprint arXiv:2406.13144},
year = {2024},
}